I actually do this already via a direct dump as you mentioned. A cron runs for daily, weekly, and monthly which dumps the database and uploads it to Amazon AWS (externally) so that there is always a backup available, and multiple versions just in case the latest backups are the corrupted version you no longer want.
Here is the shell script I use that is executed via cron job:
#!/bin/sh
FILENAME="db-backup.sql"
NOW=$(date +"%Y-%m-%d")
if [ "$1" = 'weekly' ]
then
PATH="backup/weekly"
elif [ "$1" = 'monthly' ]
then
PATH="backup/monthly"
else
PATH="backup/daily"
fi
/usr/bin/mysqldump -u username -p database > $NOW-$FILENAME
/usr/bin/gzip -f $NOW-$FILENAME.gz
/usr/bin/s3cmd put $NOW-$FILENAME.gz s3://your-bucket-name/$PATH/
/usr/bin/rm $NOW-$FILENAME.gz
Your crontab for having this script execute might look like this:
45 0 * * * /path/to/script.sh daily
45 1 * * 0 /path/to/script.sh weekly
45 2 15 * * /path/to/script.sh monthly
Explanation of the cron for each respective line number:
- Runs daily at 12:45 am
- Runs weekly on Sunday at 1:45 am
- Runs monthly on the 15th of the month at 2:45 am.
The first argument for the script (daily, weekly, monthly) will help determine how it is stored in Amazon S3, it will make sense if you analyze how the script is written. Thus you will need an Amazon S3 bucket setup, in this example its called your-bucket-name, and then the respective folders: daily, weekly, monthly:
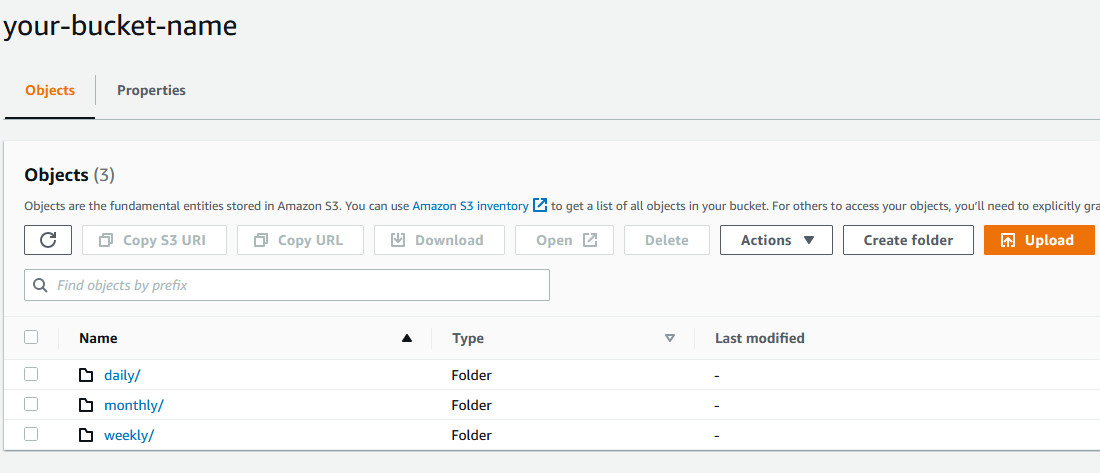
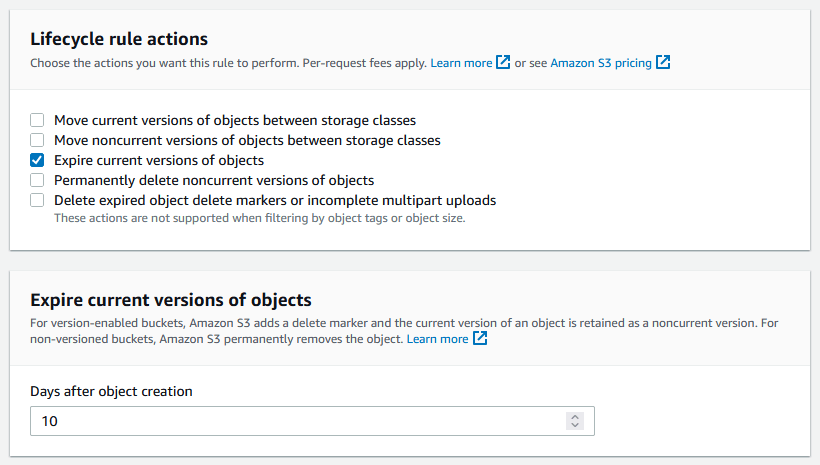
You can set up lifecycle rules with Amazon S3 to only keep a certain number of backups to suit your needs for how long you want to retain the data. Here is an example of the rules I have setup:
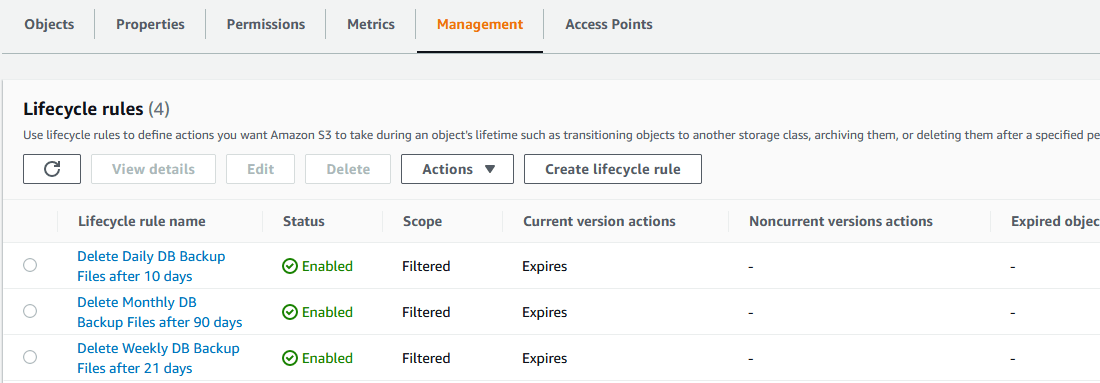
In each rule, I check the box to Expire current versions of objects, and then set to expire after a number of days: